
Greetings, travelers, who may have come to this page by way of my other page on this subject, dealing with the same subject matter, but with logstash version 1.1.x.
Logstash 1.2.1 is brand new as of this edition. The changes to my Apache CustomLog JSON recipe are in! I’ve even since updated this page to not use the prune filter but exclusively use the new logstash conditionals.
Apache configuration:
LogFormat "{
"@timestamp": "%{%Y-%m-%dT%H:%M:%S%z}t",
"@version": "1",
"vips":["vip.example.com"],
"tags":["apache"],
"message": "%h %l %u %t \"%r\" %>s %b",
"clientip": "%a",
"duration": %D,
"status": %>s,
"request": "%U%q",
"urlpath": "%U",
"urlquery": "%q",
"bytes": %B,
"method": "%m",
"referer": "%{Referer}i",
"useragent": "%{User-agent}i"
}" ls_apache_json
CustomLog /var/log/apache2/logstash_test.ls_json ls_apache_json
Logstash configuration:
input {
file {
path => "/var/log/apache2/*.ls_json"
tags => "apache_json"
codec => "json"
}
}
filter {
geoip {
add_tag => [ "GeoIP" ]
database => "/opt/logstash/GeoLiteCity.dat"
source => "clientip"
}
if [useragent] != "-" and [useragent] != "" {
useragent {
add_tag => [ "UA" ]
source => "useragent"
}
}
if [bytes] == 0 { mutate { remove => "[bytes]" } }
if [geoip][city_name] == "" { mutate { remove => "[geoip][city_name]" } }
if [geoip][continent_code] == "" { mutate { remove => "[geoip][continent_code]" } }
if [geoip][country_code2] == "" { mutate { remove => "[geoip][country_code2]" } }
if [geoip][country_code3] == "" { mutate { remove => "[geoip][country_code3]" } }
if [geoip][country_name] == "" { mutate { remove => "[geoip][country_name]" } }
if [geoip][latitude] == "" { mutate { remove => "[geoip][latitude]" } }
if [geoip][longitude] == "" { mutate { remove => "[geoip][longitude]" } }
if [geoip][postal_code] == "" { mutate { remove => "[geoip][postal_code]" } }
if [geoip][region_name] == "" { mutate { remove => "[geoip][region_name]" } }
if [geoip][time_zone] == "" { mutate { remove => "[geoip][time_zone]" } }
if [urlquery] == "" { mutate { remove => "urlquery" } }
if "apache_json" in [tags] {
if [method] =~ "(HEAD|OPTIONS)" { mutate { remove => "method" } }
if [useragent] == "-" { mutate { remove => "useragent" } }
if [referer] == "-" { mutate { remove => "referer" } }
}
if "UA" in [tags] {
if [device] == "Other" { mutate { remove => "device" } }
if [name] == "Other" { mutate { remove => "name" } }
if [os] == "Other" { mutate { remove => "os" } }
}
}
output {
elasticsearch {
host => "elasticsearch.example.com"
cluster => "elasticsearch"
}
}
So let’s analyze these. The apache configuration now has no nesting in @fields (and there was much rejoicing), so it is considerably less cluttered. We’re writing to file here, and making the file end in ls_json (for convenience’s sake). Aside from this, there’s almost nothing different here between 1.1.x and 1.2.x configuration.
In the logstash configuration there are some big changes under the hood. Let’s look at the input first:
input {
file {
path => "/var/log/apache2/*.ls_json"
tags => "apache_json"
codec => "json"
}
}
It’s clear we’re tailing a file here, still, so that’s the same. We’re appending the tag “apache_json” for ourselves. I opted to do this because there may be some non-json files I can’t consume this way and I want to differentiate.
The big difference here is codec. In the old example we had format => “json_event” for pre-formatted content. In Logstash 1.2.x you use a codec definition to accomplish this, but it’s not a json_event any more. The only reserved fields in logstash now are @timestamp and @version. Everything else is open.
Moving on to the filters now:
geoip {
add_tag => [ "GeoIP" ]
database => "/opt/logstash/GeoLiteCity.dat"
source => "clientip"
}
The GeoIP filter is a wonderful addition since the early days of logstash. I won’t do more than provide a link and a basic description here. It extracts all kinds of useful data about who is visiting your web server: countries, cities, timezone, latitude and longitude, etc. Not every IP will populate every field, but we’ll get to that a bit later. Use the “source” directive to specify which field holds the IP (or host) to provide to the GeoIP filter.
if [useragent] != "-" and [useragent] != "" {
useragent {
add_tag => [ "UA" ]
source => "useragent"
}
}
Awesome new Logstash feature: Conditionals. Conditionals finally provide the kind of if/then/else logic that allows you to do amazing things (and probably some pretty mundane things too, ed.). Follow the link and read up on it. I’ll follow the simple flow here a bit. If the field useragent (fields are encapsulated in square braces) is not a hyphen, and is also not empty, then perform the action, which is another filter: useragent. The useragent filter breaks down a useragent string, like “Mozilla/5.0 (iPhone; CPU iPhone OS 6_1_4 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10B350 Safari/8536.25” into useful fields, like device, os, major, minor, and name. If it can’t find the answer to some of these, it will populate them with “Other,” which I don’t want. So to save me some trouble, I will prevent this from happening by using the conditional. If it does succeed I will tag it with “UA” and it will parse the “useragent” field.
if [bytes] == 0 { mutate { remove => "[bytes]" } }
Another conditional here. Logstash will check to see if the bytes field is 0. If it is, it will remove the bytes field. This is more about clutter removal than anything else.
The remaining simple “remove” statement for empty GeoIP fields should be pretty simple to follow. One thing to note is that nested fields must be encapsulated as above within square braces, e.g. [geoip][postal_code], for proper parsing.
if "apache_json" in [tags] {
if [method] =~ "(HEAD|OPTIONS)" { mutate { remove => "method" } }
if [useragent] == "-" { mutate { remove => "useragent" } }
if [referer] == "-" { mutate { remove => "referer" } }
}
Here we are checking to see if the tag “apache_json” is in the array “tags” before proceeding with other conditionals. Note that the check for “method” is using a regular expression, so it uses =~ instead of ==, and is seeing if the entry is for either “HEAD” or “OPTIONS” and will remove the “method” field in either case.
If you are especially observant you may have noticed that there is no date filter in this example, though there was in the 1.1.x example linked above. The reason here is that the timestamp is already properly formatted in ISO8601 and logstash can see that and uses it automatically. This saves a few cycles and keeps the configuration file appearing clean and orderly.
output {
elasticsearch {
host => "elasticsearch.example.com"
cluster => "elasticsearch"
}
And we can’t let all of this expanded data go to waste, now can we. So we ship it out to elasticsearch where Kibana can get to it. Let’s take a quick look at what it looks like:
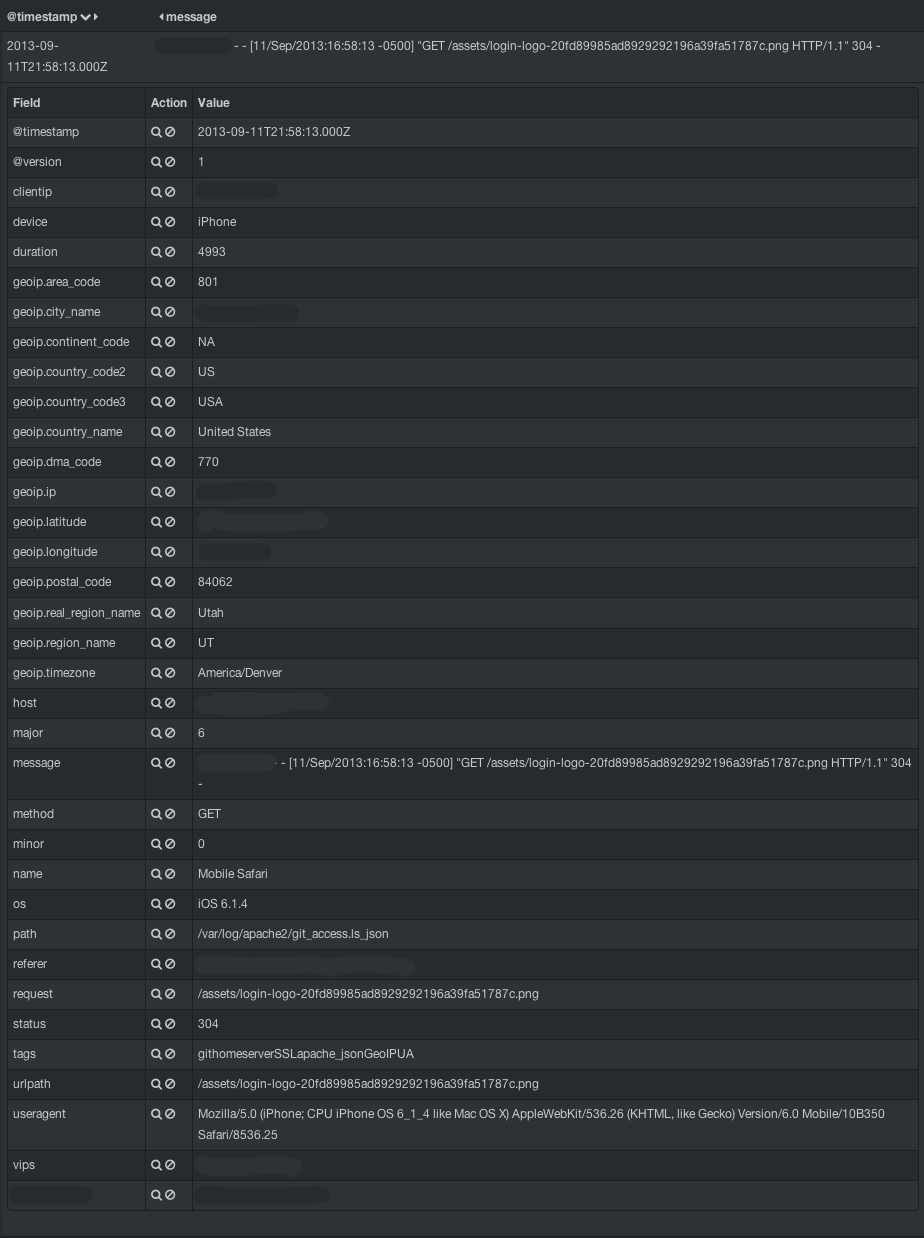
I’ve anonymized some of the data, but you can see that there are many more fields than just those few we capture from apache.
So, that’s my updated rendition of getting Apache to put JSON into logstash directly. What do you think?
I would love to hear your comments, corrections and ideas.
