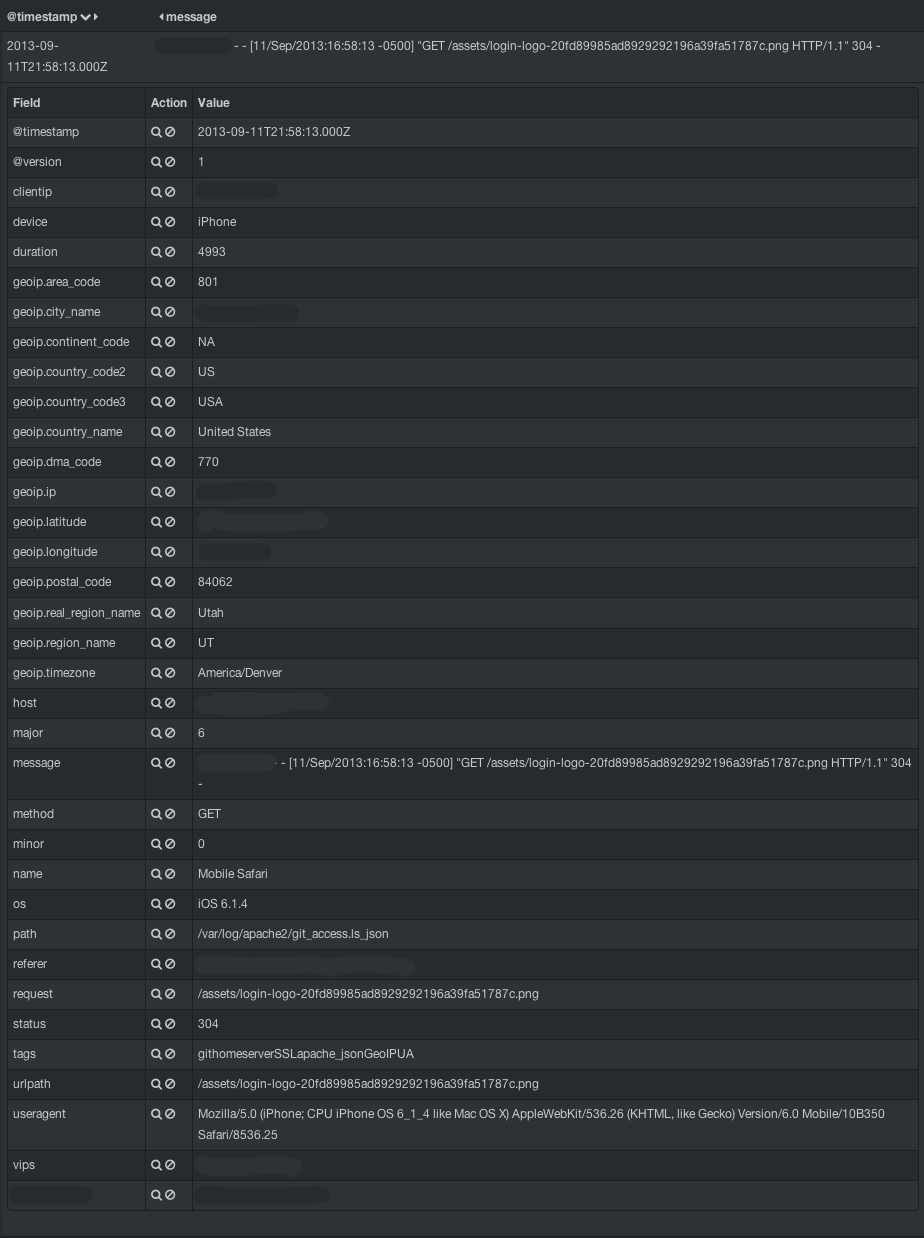
I figured it was time to share my current template again, as much has changed since Logstash 1.2. Among the changes include:
- doc_values everywhere applicable
- Defaults for all numeric types, using doc_values
- Proper mapping for the raw sub-field
- Leaving the message field analyzed, and with no raw sub-field
- Added ip, latitude, and longitude fields to the geoip mapping, using doc_values
If you couldn’t tell, I’m crazy about doc_values. Using doc_values (where permitted) prevents your elasticsearch java heap size from growing out of control when performing large aggregations—for example, a months worth of data with Kibana—with very little upfront cost in additional storage.
This is mostly generic, but it does have a few things which are specific to my use case (like the Nginx entry). Feel free to adapt to your needs.
{
"template" : "logstash-*",
"settings" : {
"index.refresh_interval" : "5s"
},
"mappings" : {
"_default_" : {
"_all" : {"enabled" : true, "omit_norms" : true},
"dynamic_templates" : [ {
"message_field" : {
"match" : "message",
"match_mapping_type" : "string",
"mapping" : {
"type" : "string", "index" : "analyzed", "omit_norms" : true
}
}
}, {
"string_fields" : {
"match" : "*",
"match_mapping_type" : "string",
"mapping" : {
"type" : "string", "index" : "analyzed", "omit_norms" : true,
"fields" : {
"raw" : {"type": "string", "index" : "not_analyzed", "doc_values" : true, "ignore_above" : 256}
}
}
}
}, {
"float_fields" : {
"match" : "*",
"match_mapping_type" : "float",
"mapping" : { "type" : "float", "doc_values" : true }
}
}, {
"double_fields" : {
"match" : "*",
"match_mapping_type" : "double",
"mapping" : { "type" : "double", "doc_values" : true }
}
}, {
"byte_fields" : {
"match" : "*",
"match_mapping_type" : "byte",
"mapping" : { "type" : "byte", "doc_values" : true }
}
}, {
"short_fields" : {
"match" : "*",
"match_mapping_type" : "short",
"mapping" : { "type" : "short", "doc_values" : true }
}
}, {
"integer_fields" : {
"match" : "*",
"match_mapping_type" : "integer",
"mapping" : { "type" : "integer", "doc_values" : true }
}
}, {
"long_fields" : {
"match" : "*",
"match_mapping_type" : "long",
"mapping" : { "type" : "long", "doc_values" : true }
}
}, {
"date_fields" : {
"match" : "*",
"match_mapping_type" : "date",
"mapping" : { "type" : "date", "doc_values" : true }
}
} ],
"properties" : {
"@timestamp": { "type": "date", "doc_values" : true },
"@version": { "type": "string", "index": "not_analyzed", "doc_values" : true },
"clientip": { "type": "ip", "doc_values" : true },
"geoip" : {
"type" : "object",
"dynamic": true,
"properties" : {
"ip": { "type": "ip", "doc_values" : true },
"location" : { "type" : "geo_point", "doc_values" : true },
"latitude" : { "type" : "float", "doc_values" : true },
"longitude" : { "type" : "float", "doc_values" : true }
}
}
}
},
"nginx_json" : {
"properties" : {
"duration" : { "type" : "float", "doc_values" : true },
"status" : { "type" : "short", "doc_values" : true }
}
}
}
}
You can also find this in a GitHub gist.
Feel free to add any suggestions, or adaptations you may have used in the comments below!